Uma Introdução Ao Deep Learning Em 2024
Introdução
Andrej Karpathy argumenta há alguns anos que o Deep Learning pode ser visto como o software 2.0, uma mudança de paradigma na maneira como é escrito mas que preserva várias das características do software que conhecemos. O Deep Learning não é propriamente escrito, mas uma série de módulos são colocados em sequência e realizam um processo matemático de otimização. Ou seja, criamos modelos compostos por várias camadas, como um arquiteto desenharia uma bela mansão dentro de uma montanha, com uma cachoeira que cai logo a sua frente e que é partida ao meio coincidentemente para que o dono possa vislumbrar o horizonte. Nós apenas criamos em nossa mente (ou desenhamos) modelos que imaginamos ter certa capacidade, mas cabe a um outro processo trazer do ato à potência a utilidade real do modelo, este processo conhecemos hoje como descida de gradiente estocástica, mas alguns cientistas são ferrenhos em afirmar que a verdadeira capacidade de nossos modelos só será explorada quando não dependermos de algo tão simples e passarmos a algo mais sofisticado.
Não é a primeira vez que não somos nós a trazer ideias do ato a potência na civilização humana, não fazemos carros com as nossas próprias mãos, nem construímos prédios de 50 andares com elas. Mas talvez seja sim a primeira vez em que uma máquina é a única capaz de trazer o conceito do ato a potência. Poderiamos construir um único carro com as próprias mãos utilizando de vários homens, ou mesmo construiriamos o mais alto dos prédios como um dia fizeram os egípcios, mas é impossível que calculassemos com nossas próprias mãos os mais de 100 bilhões de valores arbitrários que compõe um único dos modernos modelos.
Mas isto é tão assustador assim? Já não conseguiriamos sem as máquinas produzir os computadores que hoje possuímos, quando olhamos para o assunto como abstrações responsáveis por trazer de fato conceitos para a realidade, já há algum tempo estamos construíndo ferramentas que temos grande dificuldade de produzir, a ponto de criarmos máquinas que as produzem. Você sabia que existem só duas empresas que produzem máquinas que produzem os chips de 3 ou 7 nanometros? A ASML e a TSMC, caso nunca tenha ouvido falar nelas terá agora um novo entendimento entre a tensão de China e EUA/Taiwan.
A Intêligencia Artificial como é chamada, e que sob certo ponto de vista não tem nada de inteligência, é só mais uma dessas ferramentas, e que certamente será responsável por ser a produtora de outras ferramentas as quais não poderiamos construir com nossas próprias mãos, assim como as máquinas já foram. Ao meu ver, como seres humanos, sempre fomos ótimos fabricantes de fábricas, então me parece natural o ponto em que estamos.
Os computadores podem aprender tarefas sem serem programados para tal. No passado escreveriamos algoritmos extremamente complexos para identificar se em uma imagem há um gato ou se há um cachorro, afinal, escrever tal software com as próprias mãos não é nada trivial, foram necessários milhares de anos de evolução para que o cérebro de várias espécies começassem a identificar objetos no mundo e tirar conclusões disso.
Hoje, sabemos que a abordagem mais simples e correta que alguém com pouco conhecimento em Python e (em minha opinião) nenhum conhecimento em Deep Learning pode fazer em 1 dia útil é treinar uma rede convolucional (CNN), algo que já possui milhares de tutoriais na internet, e 99% deles funcionam! Para o novato, basta baixar uma conjunto de imagens e rodar 5 ou 6 células em um Jupyter Notebook, e no final dele, já será capaz de utilizar qualquer imagem de gato ou cachorro como entrada e ter uma resposta acurada do computador! Isto era completamente inimaginável antes de 2012 com o advento da AlexNet, e certamente ainda seria inimaginável sem a existência de frameworks tão fáceis de utilizar como o PyTorch e linguagens como o Python.
Já há um certo tempo venho me perguntando o que seria o “Hello world” atual para o universo do Deep Learning hoje em 2024. Quando comecei a estudar em 2020, os Transformers já eram algo super popular, mas nossos modelos ainda eram BERT e GPT2, estavamos longe de modelos como o ChatGPT e Llama, ou de ferramentas magnificas como os modelos de difusão que criam imagens a partir do texto (Dall-e, Stable Diffusion).
O “Hello World” que fiz em 2020 era exatamente o que descrevi acima, um conjunto de imagens de cães e gatos, Python, Pytorch e um Jupyter notebook encontrado na internet (para muitos, o Google Colab, como eu trabalhava há cerca de 10 meses com Python já conhecia as ferramentas básicas como o Jupyter no vscode). Após simplesmente rodar as células e ver a mágica acontecer, meu único trabalho era ler o código e tentar entender o que era tudo aquilo. O que é conv2d? o que é este optimizer.Adam? As peças já estavam todas encaixadas, o meu único trabalho era justamente entender como tudo aquilo se conectava, era como se o quebra-cabeças estivesse montado mas eu não pudesse ver onde as peças se encaixavam. Sem saber onde e como as peças se encaixam não é possível montar um outro quebra-cabeças, e este que estava em minhas mãos foi montado por alguma outra pessoa.
Quando finalizei o “Hello World”, meus próximos passos foram baixar outro conjuntos de imagens e sair da classificação binária para a classificação de N classes! E se você já fez este exercício, certamente conhece o sentimento que surge de ser o ser humano mais sábio deste planeta ao ver corretamente o nome da classe acima de diferentes imagens.
Caso tenha curiosidade, tenho em meu github o exato experimento que realizei naquele ano: https://github.com/GabrielDornelles/ResNet-18-PyTorch-Transfer-Learning-Cats-and-Dogs-breed-classification
O mundo evoluiu muito. Os Transformers estão em todos os lugares e cada vez mais eles saem do mundo acadêmico e nichado que antes habitavam e passam a entrar na vida das pessoas que não possuem conhecimento algum sobre computação. Veja, há nutricionistas utilizando o ChatGPT! Ilustradores utilizando o Stable Diffusion e ferramentas semelhantes! De maneira até distópica, há até figuras importantes gerando fake news com vídeos falsos onde é díficil dizer se o visual é real ou gerado por um modelo de Deep Learning, e a voz… Ahh a voz, é difícil diferenciar da real em muitos casos, certamente a essa altura você já ouviu as mais diferentes figuras (que não possuem nenhuma habilidade de canto) cantarem as mais diferentes músicas, trazendo aos seus ouvidos um sentimento estranho porém magnifico que é ouvir exatamente como você imaginou que fosse, mas apenas em sua imaginação jamais poderia conceber como de fato o som é.
Tanto a parte textual quanto visual estão em alta hoje, e felizmente elas podem ser compostas pelos mesmos módulos, o Transformer, algo que não era possível há poucos anos atrás, onde texto, visão e áudio eram áreas completamente distintas. Deixarei de fora neste momento o áudio, quem sabe ele não estará incluido no “Hello World” de daqui alguns anos?
Meu objetivo é trazer um “Hello World” que incorpora o básico dos Transformers em uma tarefa que envolva imagens e texto, e para isso escolhi a tarefa de image-captioning, que consiste em descrever o que está acontecendo em uma imagem. Com estes conhecimentos, é possível começar os estudos em modelos específicos de texto, ou modelos específicos de imagem, e também ter um vislumbre de como essas coisas se encaixam.
Parando pra pensar, que desperdicio é escrever sobre esse assunto! Afinal daqui dois anos é muito provável que o “Hello World” já seja outro…
Mas de qualquer maneira, é com a convicção de que talvez este documento possa ser útil a alguém que estou escrevendo. E no pior dos casos, vai ser um fruto que irá me gerar nostalgia em algum futuro próximo.
Objetivo
O objetivo técnico a resolvermos é o seguinte:
- Um modelo capaz de descrever com texto o que está acontecendo em imagens
- O modelo deve ser feito com módulos e blocos da arquitetura Transformers
- Não deve possuir redes como LSTM, GRUs ou mesmo Redes convolucionais.
Lembre-se que algumas destas restrições só foram colocadas para nos forçarmos a aprender algumas coisas novas, e que há modelos que utilizam de qualquer uma das 3 redes as quais não iremos utilizar.
Todo o conteúdo abaixo pode ser encontrado no repositório image-to-text-transformer, você poderá reproduzir ou alterar o código. O mesmo é suficiente para rodar todo o conteúdo que iremos ver na sequência.
Table of Contents
- Flickr Dataset
- Texto e Tokenização
- Patch Embedding
- Embeddings
- Transformer
- Treinamento
- Resultados
Flickr Dataset
Diversos datasets podem ser utilizados para a tarefa de image captioning. O que escolhi para o nosso exercício é o menor que encontrei, o Flickr. Este dataset possui 30 mil imagens, o que já é algo bastante robusto. Para nosso exercício fui ainda mais longe em diminuir o dataset, utilizando um subset deste chamado Flickr8k, que contém 8 mil imagens e 5 captions para cada uma delas (5 diferentes descrições para cada uma das imagens).
Verá que a maneira como o dataset está distribuido é bastante simples, imagens em um diretório e um “.txt” separado por vírgulas onde o primeiro item é o nome da imagem e o segundo é a descrição da mesma. Após ter aprendido este experimento sinta-se a vontade para treinar modelos maiores em datasets maiores, o dataset COCO2014 para image captioning possui ~82 mil imagens, certamente utiliza-lo para o treino resultará em um modelo muito mais robusto.
Texto e Tokenização
Escreverei neste tópico de maneira resumida, mas presumindo que você talvez nunca tenha trabalhado com texto no deep learning. A tokenização precede os Transformers, e já era utilizada claro antes do advento da arquitetura. Trata-se de representar texto como nós humanos conhecemos numericamente. O método mais rudimentar consiste em mapear letras para tokens, como o alfabeto para a numeração 0-25. Dessa maneira as palavras seriam representadas da seguinte maneira:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
"casa": => c: 2 a: 0 s: 18 a: 0
Tokenização: [2, 0, 18, 0]
"sol" => s:18 o:14 l:11
Tokenização: [18, 14, 11]
"gato" => g: 6 a: 0 t: 19 o: 14
Tokenização: [6, 0, 19, 14]
"lua" => l: 11 u: 20 a: 0
Tokenização: [11, 20, 0]
"rio" => r: 17 i: 8 o: 14
Tokenização: [17, 8, 14]
Como pode ver, este método confere a capacidade de 1-1 de letras em uma frase para elementos em um array.
Representações mais atuais contemplam palavras inteiras, uma vez que isto aumenta consideravelmente a quantidade de texto que podemos passar a um mesmo modelo. Tokenizar as palavras seria um processo longo e árduo, mas não se preocupe, existem ferramentas prontas (as quais devemos usar para facilitar nossas vidas) que realizam essa tokenização. Utilizarei aqui o spacy, mas saiba que existem outros como por exemplo os tokenizadores da biblioteca transformers do huggingface:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import spacy
# Load English tokenizer, tagger, parser and NER
spacy_eng = spacy.load("en_core_web_sm")
# Process whole documents
text = ("In a cozy cottage nestled in the woods, there lived a curious rabbit named Flopsy. "
"One day, while hopping through the forest, Flopsy discovered a sparkling crystal hidden among the ferns. "
"Mesmerized by its beauty, Flopsy decided to share the crystal with all the woodland creatures, "
"spreading joy and wonder throughout the forest. "
"From that day on, Flopsy became known as the 'Keeper of Happiness', "
"and the forest echoed with laughter and gratitude.")
tokenized = [tok.text.lower() for tok in spacy_eng.tokenizer(text)]
print(tokenized)
>>> ['in', 'a', 'cozy', 'cottage', 'nestled', 'in', 'the', 'woods', ',', 'there', 'lived', 'a', 'curious',
'rabbit', 'named', 'flopsy', '.', 'one', 'day', ',', 'while', 'hopping', 'through', 'the', 'forest', ',',
'flopsy', 'discovered', 'a', 'sparkling', 'crystal', 'hidden', 'among', 'the', 'ferns', '.', 'mesmerized',
'by', 'its', 'beauty', ',', 'flopsy', 'decided', 'to', 'share', 'the', 'crystal', 'with', 'all', 'the',
'woodland', 'creatures', ',', 'spreading', 'joy', 'and', 'wonder', 'throughout', 'the', 'forest', '.',
'from', 'that', 'day', 'on', ',', 'flopsy', 'became', 'known', 'as', 'the', "'", 'keeper', 'of', 'happiness',
"'", ',', 'and', 'the', 'forest', 'echoed', 'with', 'laughter', 'and', 'gratitude', '.']
Veja este mesmo exemplo com um tokenizador da biblioteca transformers:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# pip3 install transformers
from transformers import AutoTokenizer
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
# Process whole documents
text = ("In a cozy cottage nestled in the woods, there lived a curious rabbit named Flopsy. "
"One day, while hopping through the forest, Flopsy discovered a sparkling crystal hidden among the ferns. "
"Mesmerized by its beauty, Flopsy decided to share the crystal with all the woodland creatures, "
"spreading joy and wonder throughout the forest. "
"From that day on, Flopsy became known as the 'Keeper of Happiness', "
"and the forest echoed with laughter and gratitude.")
tokenized = tokenizer.tokenize(text)
print(tokenized)
>>> ['in', 'a', 'cozy', 'cottage', 'nestled', 'in', 'the', 'woods', ',', 'there', 'lived', 'a', 'curious',
'rabbit', 'named', 'flop', '##sy', '.', 'one', 'day', ',', 'while', 'hopping', 'through', 'the', 'forest',
',', 'flop', '##sy', 'discovered', 'a', 'sparkling', 'crystal', 'hidden', 'among', 'the', 'ferns', '.',
'me', '##sm', '##eri', '##zed', 'by', 'its', 'beauty', ',', 'flop', '##sy', 'decided', 'to', 'share', 'the',
'crystal', 'with', 'all', 'the', 'woodland', 'creatures', ',', 'spreading', 'joy', 'and', 'wonder', 'throughout',
'the', 'forest', '.', 'from', 'that', 'day', 'on', ',', 'flop', '##sy', 'became', 'known', 'as', 'the', "'",
'keeper', 'of', 'happiness', "'", ',', 'and', 'the', 'forest', 'echoed', 'with', 'laughter', 'and', 'gratitude', '.']
Você verá algumas diferenças entre os tokenizadores, mas de maneira geral utilize o que preferir, mas lembre-se que os tokenizadores disponibilizados pelo huggingface são os mesmos utilizados nos modelos como BERT e GPT, dessa maneira eles certamente tem alguma vantagem comparado a outros (mas não tenho certeza a respeito disso).
Após separar nosso texto em diferentes palavras, basta que agora criemos um dicionário onde cada palavra representa um número. Chamamos esse dicionário de vocabulário. Darei um exemplo de uma classe vocabulário uma vez que implementaremos nela todas as funcionalidades discutidas até então:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
class Vocabulary:
def __init__(self):
self.itos = {0: "<PAD>", 1: "<SOS>", 2: "<EOS>", 3: "<UNK>"}
self.stoi = {"<PAD>": 0, "<SOS>": 1, "<EOS>": 2, "<UNK>": 3}
self.freq_threshold = freq_threshold
@staticmethod
def tokenizer_eng(text):
return [tok.text.lower() for tok in spacy_eng.tokenizer(text)]
def build_vocabulary(self, sentence_list):
"""
Sentence list is a list of long strings just like the above example
"""
frequencies = {}
idx = 4
for sentence in sentence_list:
for word in self.tokenizer_eng(sentence):
if word not in frequencies:
frequencies[word] = 1
else:
frequencies[word] += 1
if frequencies[word] == self.freq_threshold:
self.stoi[word] = idx
self.itos[idx] = word
idx += 1
def numericalize(self, caption):
tokenized_text = self.tokenizer_eng(caption)
numericalized = [self.stoi[token] if token in self.stoi else self.stoi["<UNK>"] for token in tokenized_text]
return numericalized
Inicializamos nossos dicionários itos e stoi (index-to-string, string-to-index) com alguns tokens especiais, são eles:
- O token que demarca o ínicio da frase (SOS > start of sentence),
- O fim (EOS > end of sentence),
- O desconhecido (UNK > unknown, para palavras que fujam do vocabulário que possuímos)
- um token de padding (PAD > padding), que utilizaremos para transformarmos todos os nossos pares de imagem-texto em um tamanho fixo (e isto nos possibilita treinar em batches).
Em seguida temos os métodos tokenizer_eng o qual foi introduzido acima e tem a função de separar uma string em palavras que serão tokenizadas, e nosso método build_vocabulary que irá receber todas as descrições de nossas imagens e popular nosso vocabulário. Uma limitação foi colocada aqui para construirmos o vocabulário apenas com palavras que apareçam pelo menos N vezes (n=5 em meu exemplo), introduzida aqui somente para tornarmos o modelo mais leve e mais praticável como um hello world (e verá que mesmo assim levará algumas horas para realizar um treinamento).
Por último temos o método numerizalize que irá tokenizar de fato longas strings em listas puramente numéricas que tem uma representação direta em um vocabulário conhecido, o qual acabamos de construir.
Patch Embedding
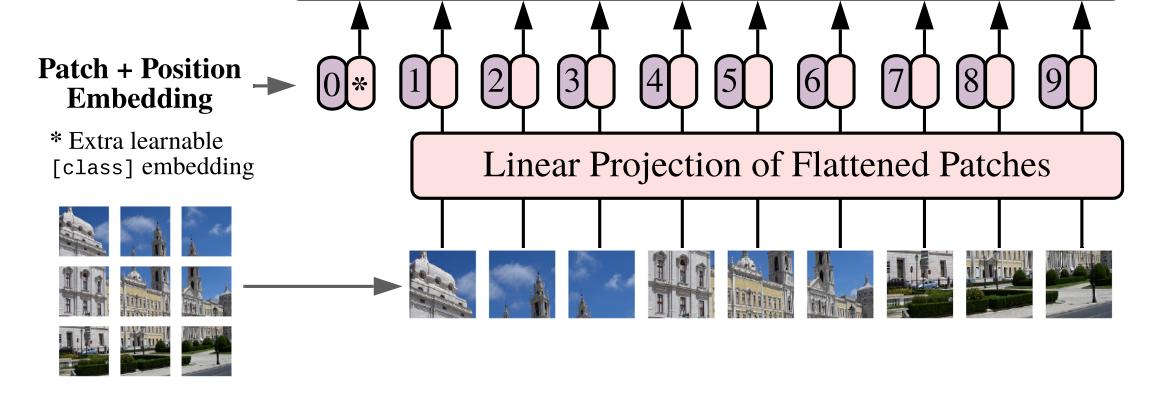
Para aqueles que já são familiares com a operação de convolução, não há nada de novo neste módulo, mas há sim algo novo na sua utilização.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class PatchEmbedding(nn.Module):
def __init__(self, img_size, patch_size, in_chans, embed_dim):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.n_patches = (img_size // patch_size) ** 2
self.patch_size = patch_size
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
# B: Batch E: Embedding P: Patch Size N: Number of patches (P*P)
x = self.proj(x) # (B, E, P, P)
x = x.flatten(2) # (B, E, N)
x = x.transpose(1, 2) # (B, N, E)
return x
O PatchEmbedding é o nosso módulo responsável por tornar a imagem um tensor semelhante ao texto que é passado aos transformers.
A ideia é que a imagem de entrada seja dividida em pequenos pedaços (chamados de patches), e esses patches sejam tratados como palavras em uma sequência de texto. Cada patch representa uma região da imagem e é tratado como uma unidade de entrada para o modelo. Isso permite que a modelo processe imagens de forma semelhante à forma como processa sequências de texto.
Este módulo é introduzido no artigo An Image is Worth 16x16 Words, perdoe-me se eu estiver errado, pois pode neste ter sido popularizado e não introduzido.
O bloco patch embeddings que vamos escrever é descrito no paper acima da seguinte maneira:
</math>
O módulo PatchEmbeddings vem juntamente de PositionalEmbeddings, que é um parâmetro treinavel que introduz a ideia de ordem nas posições dos patches que foram “amassados” até virarem tokens que podem ser usados análogamente aos tokens de texto. No modelo, o código se parecerá como abaixo:
1
2
self.patch_embed = PatchEmbedding(img_size, patch_size, in_chans, embed_dim)
self.pos_embed = nn.Parameter(torch.zeros(1, self.patch_embed.n_patches, embed_dim))
Não tenho certeza do motivo de inicializar o positional embeddings com zeros, mas encontrei múltiplas referências ao modelo ViT original enquanto fazia a minha pesquisa, e de fato, em implementações antigas do huggingface era feito desta forma.
Nos dias de hoje parece mais adequado inicializar com a distribuição normal (torch.randn), como pode ver nas implementações atuais do ViT
Feito isso, já fizemos a parte de imagem do nosso modelo. Simples assim! Apenas uma convolução com kernel_size e strides altos e operações pra alteração do shape do tensor (flatten e transpose) que serão somados a um tensor de mesmo shape que chamamos positional embeddings.
Embeddings
Os embeddings são um módulo disponível no torch.nn que funciona de maneira bastante semelhante a um nn.Linear:
1
self.trg_emb = nn.Embedding(len_vocab, embed_dim)
Perceba que é basicamente uma matriz que guarda um vetor de tamanho embed_dim para cada palavra/token em nosso vocabulário, ou seja, é como o modelo internamente irá aprender a representar cada um de nossos tokens numericamente, dessa maneira ela poderá fazer operações complexas dentro do Transformer.
Usaremos ainda um outro módulo semelhante:
1
self.trg_pos_emb = nn.Embedding(max_len, embed_dim)
Que servirá para adicionarmos a ideia de ordem em que as informações estão entrando dentro do Transformer (recomendo que dê uma olhada em Positional embeddings).
A diferença entre o nn.Embedding e o nn.Linear é que de maneira bastante simples o embedding é uma lookup table que utiliza diretamente o índice do token para acessar a sua representação, enquanto o Linear servirá para a operação de matmul. Em resumo, eles tem o mesmo formato de serem uma “matriz” NxM, porém o Embedding funciona mais como uma lista ou dicionário do que como uma matriz propriamente dita (não realiza matmul).
Transformer
Utilizaremos o transformer padrão disponiblizado pelo torch.nn, o escopo de hoje não é explicar em detalhe o funcionamento do Transformer, mas introduzi-lo e mostrar ao leitor que este módulo já é inteiramente implementado no próprio torch.nn, ou seja, não é nada especial ou com arquiteturas diferentes ou variantes de partes do mesmo (uma vez que há muitas variações dos distintos módulos que o compõe).
1
2
3
4
5
6
7
8
self.transformer = torch.nn.Transformer(
embed_dim,
nhead,
num_encoder_layers,
num_decoder_layers,
dim_feedforward,
dropout
)
O Transformer é composto de dois módulos, encoder e decoder, quando criamos com o nn.Transformer estamos criando o Transformer inteiro, mas saiba que há modelos que usam apenas o encoder ou decoder. BERT é um encoder, GPTs são decoders, porém usualmente GPTs recebem informaçoes que passam por um encoder, transformando o sistema final em um Transformer inteiro. O bloco responsável por receber N tokens e entregar o próximo é conhecido como decoder (e você já deve ter visto que a tarefa do ChatGPT é prever a próxima palavra), e é necessário um encoding destes N tokens, por isso os sistemas de GPT são transformers completos.
Nosso transformer é semelhante a um GPT, exceto que, juntamente a informação semântica (texto) ele também processa dados visuais (imagem). Já passamos por todos os módulos necessários para nosso modelo, então agora iremos construi-lo:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
class Model(pl.LightningModule):
def __init__(self,
len_vocab,
img_size=224,
patch_size=7,
in_chans=3,
embed_dim=256,
max_len=100,
nhead=2,
num_encoder_layers=3,
num_decoder_layers=3,
dim_feedforward=400,
dropout=0.1
):
super().__init__()
self.patch_embed = PatchEmbedding(img_size, patch_size, in_chans, embed_dim)
self.pos_embed = nn.Parameter(torch.zeros(1, self.patch_embed.n_patches, embed_dim))
self.trg_emb = nn.Embedding(len_vocab, embed_dim)
self.trg_pos_emb = nn.Embedding(max_len, embed_dim)
self.max_len = max_len
self.transformer = nn.Transformer(
embed_dim, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward, dropout
)
self.l = nn.LayerNorm(embed_dim)
self.fc = nn.Linear(embed_dim, len_vocab)
Nosso modelo é composto pelos seguintes blocos:
visual = PatchEmbedding + PatchPositionalEmbedding text = CaptionEmbeddings + CaptionPositionalEmbeddings output = Transformer(visual, text)
A inferência deste se parece da seguinte maneira:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
def forward(self, images, captions):
# embed images
embed_imgs = self.patch_embed(images)
embed_imgs = embed_imgs + self.pos_embed
# embed captions
B, trg_seq_len = captions.shape
trg_positions = (torch.arange(0, trg_seq_len).expand(B, trg_seq_len).to(self.device))
embed_trg = self.trg_emb(captions) + self.trg_pos_emb(trg_positions)
trg_mask = self.transformer.generate_square_subsequent_mask(trg_seq_len).to(self.device)
tgt_padding_mask = captions == 0
# transformer
y = self.transformer(
embed_imgs.permute(1,0,2),
embed_trg.permute(1,0,2),
tgt_mask=trg_mask,
tgt_key_padding_mask = tgt_padding_mask
).permute(1,0,2)
# head
return self.fc(self.l(y))
Veja que as entradas para o Transformer são o tensor de tokens das imagens e o tensor tokenizado de texto. Juntamente a essas informações, o modelo recebe uma tgt_mask, que serve para esconder durante o treinamento palavras futuras durante o processamento dos módulos de Attention¹ e tgt_key_padding_mask que serve para ignoramos os tokens que são padding (tokens que utilizamos para que todos captions sejam de um tamanho fixo). Por último passamos toda a saída do Transformer por uma LayerNorm e aplicamos um matmul com uma camada linear que irá conter probabilidades para cada token em nosso vocabulário, por fim apenas aplicaremos um argmax para descobrirmos qual o token mais provável de ser o próximo.
Para construirmos nosso transformer iremos utilizar:
1
2
3
4
5
6
7
8
9
10
11
12
model = Model(len_vocab=2994,
img_size=224,
patch_size=7,
in_chans=3,
embed_dim=256,
max_len=100,
nhead=2,
num_encoder_layers=3,
num_decoder_layers=3,
dim_feedforward=400,
dropout=0.1
)
A título de referência, o GPT2 tem 50257 palavras/tokens no seu vocabulário e seu Transformer possui 12 layers, 12 heads e embed_dim 768, totalizando 124M de parâmetros. O GPT2-medium tem a mesma arquitetura porém 24 layers, 16 heads e embed_dim 1024, totalizando 350M de parâmetros.
O Transformer é um bloco bastante complexo tanto em funcionalidades quanto em possibilidades de utilização, porém extremamente simples de implementar como deve ter percebido.
O foco de hoje não é entender em detalhe o funcionamento do Transformer, pois isso seria um outro exercício que recomendo muito que faça. O Transformer pode ser difícil de ser compreendido quando é seu primeiro contato por alguns motivos que já devem lhe ficar claros:
O Transformer possui uma inferência diferente em treino x inferência
Contrário ao que você já tenha aprendido em redes convolucionais ou arquiteturas como LSTM e GRUs, no Transformer você não faz a inferência exatamente como fez o forward pass durante o seu treinamento.
Isso ocorre por que o Transformer é um modelo auto regressivo que durante o treinamento tem acesso a respostas as quais quer treinar (até aqui é semelhante aos outros módulos que conhecemos), porém durante a inferência a resposta é desconhecida. Por conta disso, o Transformer utiliza masks em seu treinamento, algo que não tem nenhuma utilidade na inferência.
As máscaras servem justamente para prevenir que o mecanismo de atenção consiga ter acesso a informações futuras (já que durante o treinamento o modelo sabe qual a resposta esperada). Isto simula o cenário real onde iremos iniciar a inferência com o token SOS e passaremos ao modelo este token junto da imagem, feito isso, ele nos retornará um vetor de probabilidades para cada token de seu vocabulário, escolheremos o token com a maior probabilidade e faremos uma nova inferência novamente com a imagem e dessa vez 2 tokens, e repetiremos o processo N vezes ou até encontramos o token EOS que determina o fim da frase.
O Transformer pode ser utilizado de diferentes maneiras
Esta arquitetura surgiu originalmente no paper Attention Is All You Need com o objetivo de tradução entre diferentes idiomas.
Neste contexto, as entradas do Transformer são o texto tokenizado (uma frase que desejamos traduzir) e a tokenização também de sua tradução
O mesmo Transformer está sendo utilizado aqui e recebendo uma imagem tokenizada e sua resposta, o que de certa maneira pode ser pensado como estarmos traduzindo uma imagem para texto ao invés de um idioma X para um idioma Y. Verá que é possível reformular essa ideia para muitas outras tarefas.
Estude os mecanismos de Atenção
Se quiser realmente entender como as coisas funcionam por dentro do Transformer, terá que estudar os mecanismos de atenção e como funcionam, e estes provavelmente serão o real motivo que tornam difícil a compreensão da arquitetura em um primeiro contato. Atenção é um módulo que precede o Transformer, e tem duas peculiaridades por si só, em minha jornada e na de vários outros que tentaram estudar o Transformer frequentemente repetimos o mesmo erro:
Querer entender o Transformer sem antes entender tokenização, embeddings, e principalmente, os mecanismos de atenção.
Não caia na mesma armadilha que muitos de nós caíram. Será impossível compreender a funcionalidade do mesmo sem entender os módulos que o compõe.
Verá que em módulos de atenção existem context e query, e que estes dois mudam e podem assumir muitas formas em diferentes tarefas que o Transformer é utilizado. Também há keys, queries e values, que são um conceito introduzido no paper Attention Is All You Need.
The key/value/query formulation of attention is from the paper Attention Is All You Need.
The key/value/query concept is analogous to retrieval systems. For example, when you search for videos on Youtube, the search engine will map your query (text in the search bar) against a set of keys (video title, description, etc.) associated with candidate videos in their database, then present you the best matched videos (values). Reference.
Encontrará muito conteúdo rico na internet, portanto não deixe de investir tempo para entender este módulo que é tão crucial para o funcionamento de todo o conjunto.
Treinamento
O setup completo de nosso modelo está no arquivo model.py e iremos treina-lo utilizando o pytorch-lightning.
Não há nada de novo no treinamento, utilizaremos o Adam no backward pass e a função de perda é a mesma cross-entropy utilizada para classificação geral.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from dataset import Flickr8kDataModule
from model import Model
import pytorch_lightning as pl
import torch
if __name__ == "__main__":
dm = Flickr8kDataModule(batch_size=64)
dm.setup()
vocab_size = len(dm.train_ds.vocabulary)
model = Model(len_vocab=vocab_size)
trainer = pl.Trainer(
max_epochs=60,
precision=16
)
trainer.fit(model, dm)
torch.save(model.state_dict(), 'e2e_transformer_image_captioning.pth')
Resultados
Finalmente chegamos ao resultado! Pedi a alguns amigos que me enviassem algumas imagens gerais de cachorros ou cenas que envolvam veículos e pessoas (escopo abordado no treinamento). Abaixo trago alguns resultados do modelo:

Há muito espaço para melhorias. Nosso modelo possui apenas um módulo de Patch Embeddings (não há redes convolucionais profundas!) e um pequenino Transformer com um pequenino vocabulário! Nosso modelo ocupa apenas 20mbs em disco, uma resnet18 extremamente simples ocupa 44!
Espero que este documento tenha lhe sido útil, e que possa ter lhe esclarecido o quão simples as coisas podem ser no final das contas.
O que mais me admira é a quantidade de coisas fascinantes que emergem de sistemas tão simples e treinados de uma maneira tão rudimentar quando comparados a versão biológica dos organismos vivos que conhecemos. Sem sombra de dúvida há muita beleza na simplicidade.
Afinal, talvez tudo seja simples dado tempo suficiente para compreendermos.
¹ Não entrarei em detalhes, mas é uma matriz com diagonal superior -inf de maneira que o processamento do bloco de atenção não utilize os tokens seguintes ao passo atual, assim quando está processando o inicio da frase ela não terá acesso ao final (por exemplo) e desta forma não irá aprender correlações as quais não terá quando não possuir as respostas para as imagens que está recebendo.
Comments powered by Disqus.